Adding a QNAP TS-473A to my Ceph Nautilus Cluster
Table of Contents
I added a QNAP TS-473 to my Red Hat Ceph Storage 4 (Nautilus) cluster.
This is my braindump.
Install Red Hat Enterprise Linux 8.5
After initial bringup and a first install of RHEL 8.5, I re-installed RHEL 8.5 using the following kickstart file to use it as a node in my Ceph cluster.
Since I could not get the node to PXE boot, I simply put all I needed in the first install’s grub setup.
c.f. towards the end of my Ansible Playbook qnap-ryzen-general-setup-rhel8.yml, further down in this post.
kickstart file RHEL85-QNAP-TS-473A-ks.cfg (click to expand).
#version=RHEL8
# avoid using half arsed names like sda, sdb, etc
# TS-473A User Guide, page 10, says
# top is M.2 SSD slot 1
# lower is M.2 SSD slot 2
# Disks bays are numbered starting from 1, bay furthest away from the power button.
# for PCIe slots, the user guide says top is slot 1, bottom is slot 2
#
# NVMe slot 1 /dev/disk/by-path/pci-0000:03:00.0-nvme-1 (the top slot, contains a Samsung 980 500GB)
# NVMe slot 2 /dev/disk/by-path/pci-0000:04:00.0-nvme-1 (the bottom slot, contains a Crucial P2 2TB)
# HDD bay 1 /dev/disk/by-path/pci-0000:07:00.0-ata-1 (bay furthest away from the power button)
# HDD bay 2 /dev/disk/by-path/pci-0000:07:00.0-ata-2
# HDD bay 3 /dev/disk/by-path/pci-0000:09:00.0-ata-1
# HDD bay 4 /dev/disk/by-path/pci-0000:09:00.0-ata-2 (bay closest to the power button)
# reboot after installation is complete?
reboot
# OS is installed to the 500GB Samsung NVMe, that is in _M.2 SSD slot 1_, the top slot.
# all other storage is left untouched, ceph-ansible will deal with that
ignoredisk --only-use=/dev/disk/by-path/pci-0000:03:00.0-nvme-1
# Partition clearing information
# note that OS goes on a small portion os the device in bay 1, the rest will be allocated to Ceph in a separtate VG.
# so kickstarting with the below clearpart line will nuke the Ceph bits on SSD !!!
clearpart --all --initlabel --drives=/dev/disk/by-path/pci-0000:03:00.0-nvme-1
# Use graphical install
graphical
# Keyboard layouts
keyboard --vckeymap=us --xlayouts='us'
# System language
lang en_US.UTF-8
# Network information all switch ports have the respective VLAN as native
# 2.5 Gig on-board 1 ('access' network)
network --bootproto=dhcp --device=enp6s0 --ipv6=auto --activate
# 2.5 Gig on-board 2 (will go on 'storage' via ansible)
network --bootproto=dhcp --device=enp5s0 --onboot=off --ipv6=auto --no-activate
# 10 Gig on PCIe (will go on 'ceph' via ansible)
network --bootproto=dhcp --device=enp2s0f0 --onboot=off --ipv6=auto --no-activate
# 10 Gig on PCIe slot 2 (PCIe 3.0 x4), currently unused
network --bootproto=dhcp --device=enp2s0f1 --onboot=off --ipv6=auto --no-activate
# hostname will be set via ansible
network --hostname=localhost.localdomain
# Use network installation
url --url="ftp://fileserver.internal.pcfe.net/pub/redhat/RHEL/RHEL-8.5/Server/x86_64/os/BaseOS"
repo --name="AppStream" --baseurl=ftp://fileserver.internal.pcfe.net/pub/redhat/RHEL/RHEL-8.5/Server/x86_64/os/AppStream
# Root password
rootpw --iscrypted [REDACTED]
# Run the Setup Agent on first boot?
firstboot --disable
# Do not configure the X Window System
skipx
# System services
services --enabled="chronyd"
# Intended system purpose
syspurpose --role="Red Hat Enterprise Linux Server" --sla="Self-Support" --usage="Development/Test"
# System timezone
timezone Europe/Berlin --isUtc --ntpservers=[REDACTED]
# Ansible user
user --groups=wheel --name=ansible --password=[REDACTED] --iscrypted --gecos="ansible"
# Disk partitioning information
# the 500GB Samsung NVMe in slot 1 will be fully used for the OS
# the 2TB Crucial NVMe in slot 2 and the HDDs in slots 1 through 4
# will be fed to ceph-ansible as devices
# c.f. https://docs.ceph.com/ceph-ansible/master/osds/scenarios.html
part /boot --fstype="ext4" --ondisk=/dev/disk/by-path/pci-0000:03:00.0-nvme-1 --size=1024
part /boot/efi --fstype="efi" --ondisk=/dev/disk/by-path/pci-0000:03:00.0-nvme-1 --size=512 --fsoptions="umask=0077,shortname=winnt"
part pv.01 --fstype="lvmpv" --ondisk=/dev/disk/by-path/pci-0000:03:00.0-nvme-1 --size=61440 --grow
volgroup VG_OS_NVMe1 --pesize=4096 pv.01
logvol / --fstype="xfs" --size=4096 --name=LV_root --vgname=VG_OS_NVMe1
logvol swap --fstype="swap" --size=4096 --name=LV_swap --vgname=VG_OS_NVMe1
logvol /var --fstype="xfs" --size=5120 --name=LV_var --vgname=VG_OS_NVMe1
logvol /var/log --fstype="xfs" --size=4096 --name=LV_var_log --vgname=VG_OS_NVMe1
logvol /var/crash --fstype="xfs" --size=70000 --name=LV_var_crash --vgname=VG_OS_NVMe1
logvol /var/lib/containers --fstype="xfs" --size=8192 --name=LV_containers --vgname=VG_OS_NVMe1
logvol /home --fstype="xfs" --size=1024 --name=LV_home --vgname=VG_OS_NVMe1
%packages
@^minimal-environment
chrony
kexec-tools
%end
%addon com_redhat_kdump --enable --reserve-mb='auto'
%end
%anaconda
pwpolicy root --minlen=6 --minquality=1 --notstrict --nochanges --notempty
pwpolicy user --minlen=6 --minquality=1 --notstrict --nochanges --emptyok
pwpolicy luks --minlen=6 --minquality=1 --notstrict --nochanges --notempty
%end
%post --log=/root/ks-post.log
# dump pcfe's ssh key to the root user
# obviously change this to your own pubkey unless you want to grant me root access
mkdir /root/.ssh
chown root.root /root/.ssh
chmod 700 /root/.ssh
cat <<EOF >>/root/.ssh/authorized_keys
[REDACTED]
EOF
chown root.root /root/.ssh/authorized_keys
chmod 600 /root/.ssh/authorized_keys
restorecon /root/.ssh/authorized_keys
cat <<EOF >>/etc/udev/rules.d/75-disable-5GB-on-board-stick.rules
# The on-board 5GB stick should be disabled
# I currently have no use for it and leaving it untouched allows a reset to the shipped state
# by choosing the USB stick as boot target during POST
# c.f. https://projectgus.com/2014/09/blacklisting-a-single-usb-device-from-linux/
SUBSYSTEM=="usb", ATTRS{idVendor}=="1005", ATTRS{idProduct}=="b155", ATTR{authorized}="0"
EOF
chown root.root /etc/udev/rules.d/75-disable-5GB-on-board-stick.rules
chmod 644 /etc/udev/rules.d/75-disable-5GB-on-board-stick.rules
restorecon /etc/udev/rules.d/75-disable-5GB-on-board-stick.rules
# Since Ceph and EPEL should not be mixed,
# pull check-mk-agent from my monitoring server (checkmk Raw edition)
dnf -y install http://check-mk.internal.pcfe.net/HouseNet/check_mk/agents/check-mk-agent-2.0.0p15-1.noarch.rpm
echo "check-mk-agent installed from monitoring server" >> /etc/motd
# seems I can NOT specify a connection name for the network setup
# https://pykickstart.readthedocs.io/en/latest/kickstart-docs.html#network
# so just remove the line setting the name "System enp…" and then move the files
# fedora.linux_system_roles.network will do the rest later
# I do this because I find speaking names so much more pleasant
sed --in-place "s/^NAME//g" /etc/sysconfig/network-scripts/ifcfg-enp*
mv /etc/sysconfig/network-scripts/ifcfg-enp6s0 /etc/sysconfig/network-scripts/ifcfg-2.5G_1
mv /etc/sysconfig/network-scripts/ifcfg-enp5s0 /etc/sysconfig/network-scripts/ifcfg-2.5G_2
mv /etc/sysconfig/network-scripts/ifcfg-enp2s0f0 /etc/sysconfig/network-scripts/ifcfg-10G_1
mv /etc/sysconfig/network-scripts/ifcfg-enp2s0f1 /etc/sysconfig/network-scripts/ifcfg-10G_2
# disable Red Hat graphical boot (rhgb)
sed --in-place "s/ rhgb//g" /etc/default/grub
echo "kickstarted at `date` for RHEL 8.5 on QNAP TS-473A" >> /etc/motd
%end
Prep, with Ansible, for addition to Ceph Cluster
Ansible Inventory Entries
In the hosts file used by my workstation
[QNAP_Ryzen_boxes]
ts-473a-01 ansible_user=ansible
In the hosts file used by my ceph-ansible control node
[osds]
f5-422-0[1:4].storage.pcfe.net
ts-473a-01.storage.pcfe.net
group_vars/QNAP_Ryzen_boxes.yml (click to expand).
---
user_owner: pcfe
ansible_user: ansible
common_timezone: Europe/Berlin
Sets some variables used by my role pcfe.user_owner.
inventories/host_vars/ts-473a-01.yml (click to expand).
network_connections:
- name: "System 2.5G_1"
type: ethernet
interface_name: "enp6s0"
zone: "public"
state: up
persistent_state: present
ip:
dhcp4: no
auto6: yes
gateway4: 192.168.50.254
dns: 192.168.50.248
dns_search: internal.pcfe.net
address: 192.168.50.185/24
- name: "System 2.5G_2"
type: "ethernet"
interface_name: "enp5s0"
zone: "public"
state: up
persistent_state: present
ip:
dhcp4: no
auto6: yes
dns_search: storage.pcfe.net
address: 192.168.40.185/24
route_append_only: yes
- name: "System 10G_1"
type: "ethernet"
mtu: 9000
interface_name: "enp2s0f0"
zone: "public"
state: up
persistent_state: present
ip:
dhcp4: no
auto6: yes
dns_search: ceph.pcfe.net
address: 192.168.30.185/24
route_append_only: yes
# There is no need to muck around with the osd_memory_target settting on the QNAP TS-473A, it has 64 GiB RAM.
# avoid using half arsed names like sda, sdb, etc
# mapping is:
# NVMe slot 1 /dev/disk/by-path/pci-0000:03:00.0-nvme-1 (the top slot, contains a Samsung 980 500GB)
# NVMe slot 2 /dev/disk/by-path/pci-0000:04:00.0-nvme-1 (the bottom slot, contains a Crucial P2 2TB)
# HDD bay 1 /dev/disk/by-path/pci-0000:07:00.0-ata-1 (bay furthest away from the power button)
# HDD bay 2 /dev/disk/by-path/pci-0000:07:00.0-ata-2
# HDD bay 3 /dev/disk/by-path/pci-0000:09:00.0-ata-1
# HDD bay 4 /dev/disk/by-path/pci-0000:09:00.0-ata-2 (bay closest to the power button)
dmcrypt: True
osd_objectstore: bluestore
osd_scenario: lvm
devices:
- /dev/disk/by-path/pci-0000:04:00.0-nvme-1
- /dev/disk/by-path/pci-0000:07:00.0-ata-1
- /dev/disk/by-path/pci-0000:07:00.0-ata-2
- /dev/disk/by-path/pci-0000:09:00.0-ata-1
- /dev/disk/by-path/pci-0000:09:00.0-ata-2
tuned_profile: powersave
Sets variables used to configure
- network connections
- ceph-ansible
- tuned
Initial Setup
Ansible Playbook qnap-ryzen-initial-setup-rhel8.yml (click to expand).
---
# sets up a RHEL 8 minimal install to be ready for ceph-ansible
#
# the playbook runs as root (see ansible_user line below) and preps the node for normal ansible operations wit the ansible user and ensures access to Red Hat subscriptions is used.
# Expect the redhat_subscription task to take more than one but less than five minutes
#
# this is for my home setup, not for production!
- hosts:
- QNAP_Ryzen_boxes
become: false
roles:
- pcfe.user_owner
- pcfe.basic-security-setup
- pcfe.housenet
# no need for double indirect if you are OK with checking in ak details into git
# this is OK to do if you use an in-house Satellite server and your security policies allow it
# this is not a good idea if you register your systems directly to redhat.com and cannot guarantee that your git remains private
vars_files:
- "vars/subscription-manager-autoattach-ak-secrets.yml"
vars:
ansible_user: root
user_owner: ansible
common_timezone: Europe/Berlin
rhsm_activationkey: "{{ vaulted_rhsm_activationkey }}"
rhsm_org_id: "{{ vaulted_rhsm_org_id }}"
rhsm_pool_ids: "{{ vaulted_rhsm_pool_ids }}"
pre_tasks:
# work around identical UUID on each host as per https://theforeman.org/plugins/katello/nightly/troubleshooting/content_hosts.html
# The TerraMaster F5-422 boxes all have the same system-uuid :-(
# and if I look at `dmidecode -s system-uuid` that looks surprisingly regular. I'll know for sure if I ever purchase another of these
# RHSM does not like that, so override to avoid both
# "HTTP error (409 - Conflict): Request failed due to concurrent modification, please re-try.\n"
# and all 4 boxes overriding each other in insights inventory
- name: "RHSM | ensure uuid override is derived from fqdn, QNAP TS-473A all seem to have, like all F5-422 I own, the same system-uuid in DMI"
copy:
dest: "/etc/rhsm/facts/uuid_override.facts"
owner: "root"
group: "root"
mode: 0644
content: |
{"dmi.system.uuid": "{{ ansible_fqdn | to_uuid }}"}
# https://access.redhat.com/documentation/en-us/red_hat_ceph_storage/4/html-single/installation_guide/index#enabling-the-red-hat-ceph-storage-repositories-install
- name: "RHSM on the RHEL8 boxes"
block:
- name: "RHSM | ensure system is registered with my activation key"
redhat_subscription:
activationkey: "{{ rhsm_activationkey }}"
org_id: "{{ rhsm_org_id }}"
syspurpose:
usage: "Development/Test"
role: ""
service_level_agreement: "Self-Support"
tags: do_subsmgr_register
# n.b. those are the prerequisites, all repos off except BaseOS and AppStream
# the repos for MON, OSD, … will be handled in another playbook. (which no longer disables all and does not have the delay that using redhat_subscription task brings)
- name: "RHSM | disable all repositories, next task will enable needed repos"
rhsm_repository:
name: '*'
state: disabled
- name: "RHSM | ensure RHEL8 BaseOS repos needed for Ceph are enabled"
rhsm_repository:
name:
- rhel-8-for-x86_64-baseos-rpms
- rhel-8-for-x86_64-appstream-rpms
state: enabled
when: ansible_distribution == "RedHat" and ansible_distribution_major_version == "8"
tags: do_subsmgr_all
tasks:
# !!!
#
# if I ever enable EPEL, then I MUST exclude
# - ansible
# - ceph
# in the EPEL repo files to ensure no newer versions of those packages are pulled in from EPEL
#
# exclude = *ceph* nfs-ganesha-rgw rbd-mirror *ansible*
#
# !!!
#
# https://access.redhat.com/documentation/en-us/red_hat_ceph_storage/4/html-single/installation_guide/index#enabling-the-red-hat-ceph-storage-repositories-install
- name: "REPOS | ensure EPEL is disabled"
yum_repository:
name: epel
state: absent
# start by enabling time sync, RHSM operations will fail on too large time delta
# note that this uses chronyd, not ntpd.
- name: "CHRONYD | ensure chrony is installed"
package:
name: chrony
state: present
- name: "CHRONYD | ensure chrony-wait is enabled"
service:
name: chrony-wait
enabled: true
- name: "CHRONYD | ensure chronyd is enabled and running"
service:
name: chronyd
enabled: true
state: started
# enable persistent journal
# https://access.redhat.com/solutions/696893 instructs to sinmply mkdir as root, so drop the owner, group and mode lines
- name: "JOURNAL | ensure persistent logging for the systemd journal is possible"
file:
path: /var/log/journal
state: directory
# 2.10. Enabling Password-less SSH for Ansible
- name: "SUDO | enable passwordless sudo for user {{ user_owner }}"
copy:
dest: '/etc/sudoers.d/{{ user_owner }}'
content: |
{{ user_owner }} ALL=NOPASSWD: ALL
owner: root
group: root
mode: 0440
# Ensure the ansible user can NOT log in with password
- name: "Ensure the ansible user can NOT log in with password"
user:
name: '{{ user_owner }}'
password_lock: True
# Install prerequisites
# https://access.redhat.com/documentation/en-us/red_hat_ceph_storage/4/html/installation_guide/requirements-for-installing-rhcs#enabling-the-red-hat-ceph-storage-repositories-install
- name: "package | ensure prerequisites needed in addition to minimal install are present"
package:
name:
- yum-utils
- vim
state: present
That Playbook can take a moment to run because I have to do rhsm operations. It:
- ensures the node is registered with subscription-manager
- ensures prerequisites from the Red Hat Ceph Storage 4 installation guide are fulfilled
- ensures I have persistent journal logging
- ensures the ansible user, that ceph-ansible will connect as, is set up as needed
General Setup
Ansible Playbook qnap-ryzen-general-setup-rhel8.yml (click to expand).
---
- hosts:
- QNAP_Ryzen_boxes
become: true
roles:
- fedora.linux_system_roles.network
- pcfe.user_owner
- pcfe.basic-security-setup
- pcfe.housenet
- pcfe.comfort
# - pcfe.checkmk
handlers:
- name: grub2-mkconfig | run
command: grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
tasks:
# Install some tools
- name: "PACKAGE | tool installation"
package:
name:
- pciutils
- usbutils
- nvme-cli
- fio
- powertop
- tuned
- tuned-utils
- numactl
- mailx
- teamd
- NetworkManager-team
- iperf3
- tcpdump
- hwloc
- hwloc-gui
state: present
update_cache: no
# linux-system-roles.network sets static network config (from host_vars)
# but I want the static hostname nailed down too
- name: "set hostname"
hostname:
name: "{{ ansible_fqdn }}"
use: systemd
# FIXME: should also find a module to do `hostnamectl set-chassis server`
# enable watchdog
# it's a
# Dec 19 15:09:08 ts-473a-01.internal.pcfe.net kernel: sp5100_tco: SP5100/SB800 TCO WatchDog Timer Driver
# Dec 19 15:09:08 ts-473a-01.internal.pcfe.net kernel: sp5100-tco sp5100-tco: Using 0xfeb00000 for watchdog MMIO address
# and modinfo says
# parm: heartbeat:Watchdog heartbeat in seconds. (default=60) (int)
# parm: nowayout:Watchdog cannot be stopped once started. (default=0) (bool)
- name: "WATCHDOG | ensure kernel module sp5100_tco has correct options configured"
lineinfile:
path: /etc/modprobe.d/sp5100_tco.conf
create: true
regexp: '^options '
insertafter: '^#options'
line: 'options sp5100_tco nowayout=0'
# configure both watchdog.service and systemd watchdog, but only use the latter
- name: "WATCHDOG | ensure watchdog package is installed"
package:
name: watchdog
state: present
update_cache: no
- name: "WATCHDOG | ensure correct watchdog-device is used by watchdog.service"
lineinfile:
path: /etc/watchdog.conf
regexp: '^watchdog-device'
insertafter: '^#watchdog-device'
line: 'watchdog-device = /dev/watchdog0'
- name: "WATCHDOG | ensure timeout is set to 30 seconds for watchdog.service"
lineinfile:
path: /etc/watchdog.conf
regexp: '^watchdog-timeout'
insertafter: '^#watchdog-timeout'
line: 'watchdog-timeout = 30'
# Using systemd watchdog rather than watchdog.service
- name: "WATCHDOG | ensure watchdog.service is disabled"
systemd:
name: watchdog.service
state: stopped
enabled: false
# configure systemd watchdog
# c.f. http://0pointer.de/blog/projects/watchdog.html
- name: "WATCHDOG | ensure systemd watchdog is enabled"
lineinfile:
path: /etc/systemd/system.conf
regexp: '^RuntimeWatchdogSec'
insertafter: 'EOF'
line: 'RuntimeWatchdogSec=30'
- name: "WATCHDOG | ensure systemd shutdown watchdog is enabled"
lineinfile:
path: /etc/systemd/system.conf
regexp: '^ShutdownWatchdogSec'
insertafter: 'EOF'
line: 'ShutdownWatchdogSec=30'
# install and enable rngd
- name: "RNGD | ensure rng-tools package is installed"
package:
name: rng-tools
state: present
update_cache: no
- name: "RNGD | ensure rngd.service is enabled and started"
systemd:
name: rngd.service
state: started
enabled: true
# ensure tuned is set up as I wish
- name: "TUNED | ensure tuned.service is enabled and running"
systemd:
name: tuned.service
state: started
enabled: true
- name: "TUNED | check which tuned profile is active"
command: tuned-adm active
register: tuned_active_profile
ignore_errors: yes
changed_when: no
- name: "TUNED | activate tuned profile {{ tuned_profile }}"
command: "tuned-adm profile {{ tuned_profile }}"
when: not tuned_active_profile.stdout is search('Current active profile:' ~ ' ' ~ tuned_profile)
# install cockpit, but disabled for now
- name: "COCKPIT | ensure packages for https://cockpit-project.org/ are installed"
package:
name:
- cockpit
- cockpit-selinux
- cockpit-kdump
- cockpit-system
state: present
update_cache: no
- name: "COCKPIT | ensure cockpit.socket is stopped and disabled"
systemd:
name: cockpit.socket
state: stopped
enabled: False
- name: "COCKPIT | ensure firewalld forbids service cockpit in zone public"
firewalld:
service: cockpit
zone: public
permanent: True
state: disabled
immediate: True
# enable kdump.service since kickstart now creates a sufficiently large /var/crash
# alternatively, you could set up netdump
- name: "Ensure kdump.service is enabled and started"
systemd:
name: kdump.service
state: started
enabled: True
# podman
- name: "PACKAGE | ensure podman is installed"
package:
name:
- podman
- podman-docker
state: present
update_cache: no
# setroubleshoot, see also https://danwalsh.livejournal.com/20931.html
- name: "PACKAGE | ensure setroubleshoot for headless server is installed"
package:
name:
- setroubleshoot-server
- setroubleshoot-plugins
state: present
update_cache: no
- name: "MONITORING | ensure packages for monitoring are installed"
package:
name:
- smartmontools
- hdparm
- check-mk-agent
- lm_sensors
state: present
update_cache: no
- name: "MONITORING | ensure firewalld permits 6556 in zone public for check-mk-agent"
firewalld:
port: 6556/tcp
permanent: True
state: enabled
immediate: True
zone: public
- name: "MONITORING | ensure tarsnap cache is in fileinfo"
lineinfile:
path: /etc/check_mk/fileinfo.cfg
line: "/usr/local/tarsnap-cache/cache"
create: yes
- name: "MONITORING | ensure entropy_avail plugin for Check_MK is present"
template:
src: templates/check-mk-agent-plugin-entropy_avail.j2
dest: /usr/lib/check_mk_agent/plugins/entropy_avail
mode: 0755
group: root
owner: root
- name: "MONITORING | plugins from running CEE instance"
get_url:
url: "http://check-mk.internal.pcfe.net/HouseNet/check_mk/agents/plugins/{{ item }}"
dest: "/usr/lib/check_mk_agent/plugins/{{ item }}"
mode: "0755"
loop:
- smart
- lvm
- name: "MONITORING | ensure check_mk.socket is started and enabled"
systemd:
name: check_mk.socket
state: started
enabled: True
- name: "Ensure powertop autotune service runs once at boot"
systemd:
name: powertop
state: stopped
enabled: True
# I admit, the regexp is a search engine hit
# maybe using grubby(8) would be more readable
# - https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/managing_monitoring_and_updating_the_kernel/configuring-kernel-command-line-parameters_managing-monitoring-and-updating-the-kernel#what-is-grubby_configuring-kernel-command-line-parameters
# - https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/system_administrators_guide/sec-Making_Persistent_Changes_to_a_GRUB_2_Menu_Using_the_grubby_Tool
- name: "GRUB | ensure console blanking is disabled in defaults file plus handler"
lineinfile:
state: present
dest: /etc/default/grub
backrefs: yes
regexp: '^(GRUB_CMDLINE_LINUX=(?!.* consoleblank)\"[^\"]+)(\".*)'
line: '\1 consoleblank=0\2'
notify: grub2-mkconfig | run
# Since I do not manage to get these TS-473A to PXE boot, add an entry into grub
# so that I can kickstart the box after this without fiddling with a USB stick
- name: "GRUB | ensure initrd for RHEL 8.5 kickstart is present"
get_url:
url: "ftp://fileserver.internal.pcfe.net/pub/redhat/RHEL/RHEL-8.5/Server/x86_64/os/images/pxeboot/initrd.img"
dest: "/boot/initrd-kickstart-rhel85.img"
mode: "0600"
- name: "GRUB | ensure kernel for RHEL 8.5 kickstart is present"
get_url:
url: "ftp://fileserver.internal.pcfe.net/pub/redhat/RHEL/RHEL-8.5/Server/x86_64/os/images/pxeboot/vmlinuz"
dest: "/boot/vmlinuz-kickstart-rhel85"
mode: "0755"
- name: "GRUB | ensure kickstarting RHEL 8.5 entry is present"
copy:
dest: "/etc/grub.d/11_RHEL85_kickstart"
owner: "root"
group: "root"
mode: 0755
content: |
#!/bin/sh
exec tail -n +3 $0
# This file provides an easy way to add custom menu entries. Simply type the
# menu entries you want to add after this comment. Be careful not to change
# the 'exec tail' line above.
menuentry "WARNING Kickstart this box with RHEL 8.5 as a TS-473A ceph node WARNING" {
linuxefi /vmlinuz-kickstart-rhel85 ip=dhcp inst.repo=ftp://fileserver.internal.pcfe.net/pub/redhat/RHEL/RHEL-8.5/Server/x86_64/os inst.ks=ftp://fileserver.internal.pcfe.net/pub/kickstart/RHEL85-QNAP-TS-473A-ks.cfg
initrdefi /initrd-kickstart-rhel85.img
}
notify: grub2-mkconfig | run
# upgrade the box
- name: "package | ensure all updates are applied"
package:
update_cache: yes
name: '*'
state: latest
tags: apply_errata
That Playbook:
- ensures my network connections are set up to my liking and Ceph needs (
fedora.linux_system_roles.network) - ensures I have a user account on the node (
pcfe.user_owner) - ensures SELinux is in enforcing mode and password authentication for ssh is disabled (
pcfe.basic-security-setup) - ensures my user account is set up to my liking (
pcfe.comfort) - ensures some tools I like to use are installed
- ensures the hostname is set
- ensures the hardware watchdog is set up
- ensures rngd is active
- ensures my chosen tuned profile is active
- ensures Cockpit is installed
- for now ensures Cockpit is disabled
- ensures kdump is active
- ensures setroubleshoot is set up for headless operation
- ensures I can monitor the node with my Checkmk server
- ensures
powertop --auto-tuneruns once at boot - ensures I can kickstart the node from grub
- ensures all updates are applied
Copy over host_… and group_vars
Since for ceph-ansible use I need the below, I simply copy over my host_vars and group_vars shown at the start of this post to the host I use ceph-ansible on.
dmcrypt: True
osd_objectstore: bluestore
osd_scenario: lvm
devices:
- /dev/disk/by-path/pci-0000:04:00.0-nvme-1
- /dev/disk/by-path/pci-0000:07:00.0-ata-1
- /dev/disk/by-path/pci-0000:07:00.0-ata-2
- /dev/disk/by-path/pci-0000:09:00.0-ata-1
- /dev/disk/by-path/pci-0000:09:00.0-ata-2
Add to Inventory used by ceph-ansible
For today, only put OSDs on, I’ll move some daemons from F5-422 nodes to this way more powerful node later.
[osds]
f5-422-0[1:4].storage.pcfe.net
ts-473a-01.storage.pcfe.net
Run ceph-ansible
As expected, that was completely hassle-free,
[ansible@ceph-ansible ~]$ cd /usr/share/ceph-ansible
[ansible@ceph-ansible ceph-ansible]$ ansible-playbook site-container.yml
[...]
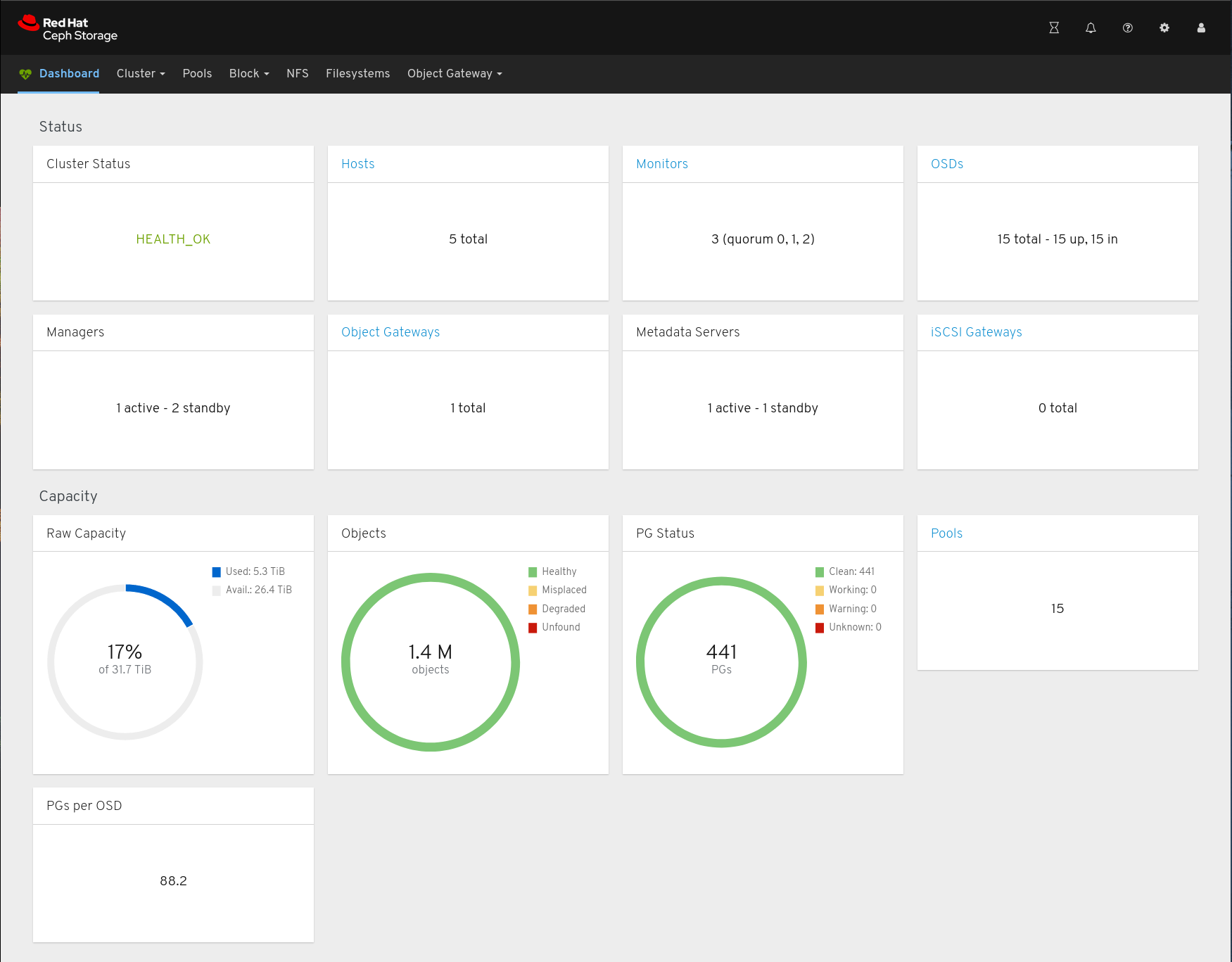
Cluster State after Expansion
[root@f5-422-01 ~]# podman exec --interactive --tty ceph-mon-f5-422-01 ceph df
RAW STORAGE:
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 32 TiB 26 TiB 5.2 TiB 5.3 TiB 16.60
TOTAL 32 TiB 26 TiB 5.2 TiB 5.3 TiB 16.60
POOLS:
POOL ID STORED OBJECTS USED %USED MAX AVAIL
cephfs_data 1 300 GiB 1.14M 1.1 TiB 4.41 7.6 TiB
cephfs_metadata 2 783 MiB 182.05k 1.2 GiB 0 7.6 TiB
.rgw.root 3 2.4 KiB 6 1.1 MiB 0 7.6 TiB
default.rgw.control 4 0 B 8 0 B 0 7.6 TiB
default.rgw.meta 5 5.0 KiB 28 4.5 MiB 0 7.6 TiB
default.rgw.log 6 3.5 KiB 208 6.2 MiB 0 7.6 TiB
libvirt 10 5.4 GiB 1.44k 16 GiB 0.07 7.6 TiB
device_health_metrics 11 49 MiB 17 49 MiB 0 7.6 TiB
rbd 12 126 B 3 192 KiB 0 7.6 TiB
default.rgw.buckets.index 13 76 KiB 55 76 KiB 0 7.6 TiB
default.rgw.buckets.data 14 14 GiB 3.84k 41 GiB 0.18 7.6 TiB
default.rgw.buckets.non-ec 15 1.5 KiB 58 11 MiB 0 7.6 TiB
ocs_rbd 17 158 GiB 41.91k 474 GiB 1.99 7.6 TiB
cinder 18 19 B 1 192 KiB 0 7.6 TiB
proxmox_rbd 19 61 GiB 34.15k 189 GiB 0.80 7.6 TiB
[root@f5-422-01 ~]# podman exec ceph-mon-f5-422-01 ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 31.68657 root default
-9 4.09348 host f5-422-01
2 hdd 1.97089 osd.2 up 1.00000 1.00000
6 hdd 1.06129 osd.6 up 1.00000 1.00000
10 hdd 1.06129 osd.10 up 1.00000 1.00000
-7 5.00307 host f5-422-02
3 hdd 1.97089 osd.3 up 1.00000 1.00000
7 hdd 1.97089 osd.7 up 1.00000 1.00000
11 hdd 1.06129 osd.11 up 1.00000 1.00000
-5 2.12259 host f5-422-03
4 hdd 1.06129 osd.4 up 1.00000 1.00000
8 hdd 1.06129 osd.8 up 1.00000 1.00000
-3 4.09348 host f5-422-04
1 hdd 1.97089 osd.1 up 1.00000 1.00000
5 hdd 1.06129 osd.5 up 1.00000 1.00000
9 hdd 1.06129 osd.9 up 1.00000 1.00000
-11 16.37396 host ts-473a-01
0 hdd 4.09349 osd.0 up 1.00000 1.00000
12 hdd 4.09349 osd.12 up 1.00000 1.00000
13 hdd 4.09349 osd.13 up 1.00000 1.00000
14 hdd 4.09349 osd.14 up 1.00000 1.00000